































药物靶点数据库作为药物研究人员在药物发现和开发过程中的关键工具,不仅能高效地挖掘探索靶点信息,还能更好指导新药的开发和现有药物的优化,广泛应用于新靶点发现、靶点药物分析、药物筛选、药物设计、疾病治疗及药理学机制的研究等领域。
随着药物研发的飞快发展使得科研人员工作变得更加专业化,随之诞生的药物靶点数据库亦是如此,这也导致科研人员在选用药物靶点数据库时不了解各个数据库的核心应用功能、数据特色特点与背景出处权威等信息。
为了帮助大家更高效地找到合适的药物靶点数据库,我深入研究了业界广泛认可的数据库,并详细阐述了它们所提供的价值数据和功能。目标是发掘并分享那些真正好用的药物靶点数据库,让大家的科研工作更加得心应手。
(注:下列数据库各具特色,并无排名先后之分)
①Therapeutic Target Database(TTD)
Therapeutic Target Database(TTD)是一个全球免费在线数据库,由TTD由新加坡国立大学开发,专注于提供药物靶标信息(有关已知和探索的治疗性蛋白质和核酸靶点、靶向疾病、通路信息以及针对每个靶点的相应药物的信息),收录了3500余个药物靶点和近4万个药物分子的信息,所有数据都有明确的参考文献支持,目标信息可以通过交叉链接从UniProtKB、PDB、KEGG、OMID和Brenda等数据库访问。
TTD靶点数据库核心功能介绍
1.靶标信息:TTD收录了3500余个药物靶点和近4万个药物分子的信息。
2.靶标筛选:TTD提出了一套基于“药、靶、病”三者关联的药靶确定策略,严格区分了“无疗效”和“有疗效”药靶的概念。
3.靶标分类:TTD将疗效靶标分为成功靶标(至少对应一种批准的药物)、临床试验靶标(对应临床试验药物,但没有批准的药物)、专利记录靶标(在专利和后续文献中引用)和文献报道的靶标。
4.数据支持和参考文献:TTD数据库中的所有数据都有明确的参考文献支持,确保了信息的溯源。
5.检索功能:用户可以通过疾病、药物或靶点来进行检索,从而获得特定疾病相关的治疗药物及药物靶点信息。
6.关于更新:TTD自2002年上线以来,已经过多次升级更新,但最近的更新日期为2024年1月10日。
②摩熵医药-药物靶点数据库(Pharnexcloud)
摩熵医药-靶点格局数据库由摩熵医药王中健博士研发,收录了全球8000+药物靶点,映射新药信息9w+条,药物发现近17w条,能快速直观地了解到全球靶点药物研发格局,包括全球同靶点新药研发信息、适应症和企业在各研发阶段的药物数量、以及国内同靶点药物和企业在各申报进度的数量。
助力把握新药研发的趋势和市场的需求变化、明确研发热点、评估竞争态势、合理布局研发管线,为研发筛选提供参考,从而提高研发效率和市场竞争力。
摩熵医药-药物靶点数据库核心功能介绍
1. 靶点研发信息整合:摩熵医药靶点数据库归纳整理了全球8000+靶点,映射新药信息9w+条,药物发现近17w条,方便快速直观地了解到全球靶点药物研发格局,包括全球同靶点新药研发信息、适应症和企业在各研发阶段的药物数量、以及国内同靶点药物和企业在各申报进度的数量。
2.靶点检索:能够通过药品名称、研发企业、靶点、药物类型、适应症、全球研发进度(靶点)、中国研发进度(靶点)等字段信息,检索出目标靶点的基本信息(功能、名称分类、亚细胞位置、疾病与变异、PTM、表达、相互作用、结构、家族、序列亚型、相似蛋白、层级关系、通路图)、全球药物研发数据、全球适应症和企业分析情况、国内品种和企业统计分析等信息。
3.靶点研发阶段筛选:通过靶点研发阶段的筛选项,方便户查找全球或中国未上市的靶点,识别潜在的药物靶点,寻找新的研发机会。
4.数据关联与拓展:该靶点数据库内多处数据关联了全球药物研发、中国药品审评、中国临床试验、中国药品批文等数据,可一键跳转查看拓展信息,助力把握新药研发的趋势和市场的需求变化、明确研发热点、评估竞争态势、合理布局研发管线,为研发筛选提供参考,从而提高研发效率和市场竞争力。
5. 靶点层级和通路信息展示:数据库提供了药物靶点的全称、别名、靶点层级关系和众多靶点通路图,通过药物靶点的层级关系图,可以看出不同靶点之间的关联。
6.靶点数据统计与分析:统计了每个靶点的统计值包含子级的所有数据,可自定义下载,也可自定义多维度动态图表分析(同靶点新药、同靶点适应症、同适应症、同靶点企业)。
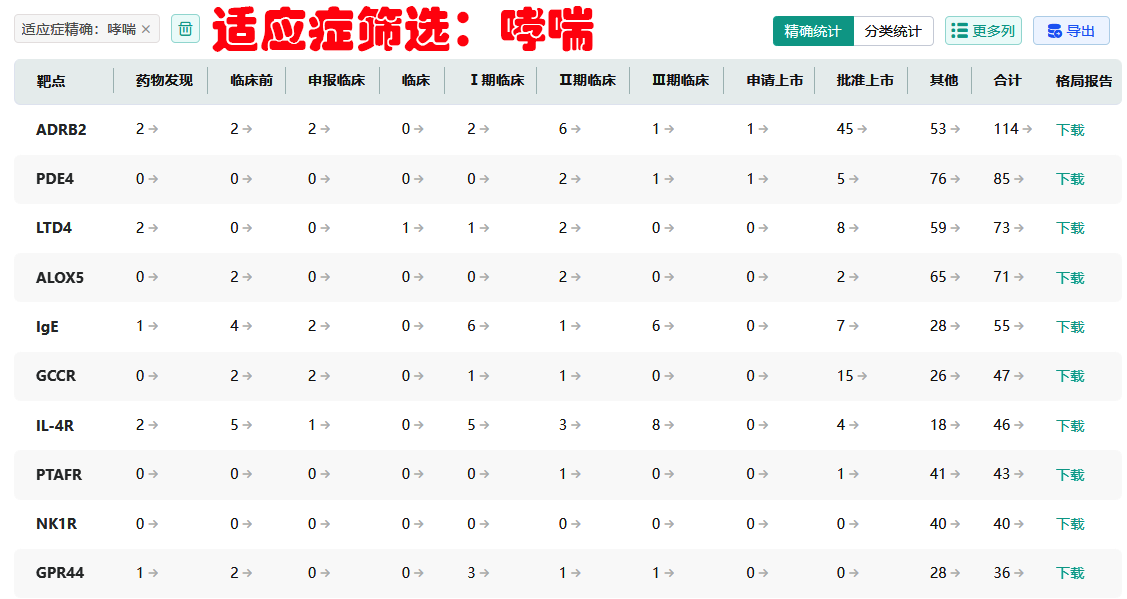
图源:摩熵医药-药物靶点数据库
③DrugBank药物靶点数据库
DrugBank药物靶点数据库由阿尔伯塔大学的David Wishart博士实验室开发,是最全面的疾病靶点数据库之一。提供了关于药物、药物作用机制、药物相互作用以及药物靶标的全面分子信息,其中包含了超过9000种药物和7100+种靶点信息。
DrugBank药物靶点数据库特点介绍
1.药物靶点数据:DrugBank提供了2723种经批准的小分子药物、1540种经批准的生物技术(蛋白质/肽)药物、131种营养品和6451种实验药物。
2. 非冗余蛋白序列:与这些药物条目相关联的有5236个非冗余蛋白(即药物靶标/酶/转运体/载体)序列。
3. 数据字段:每个DrugCard条目包含200多个数据字段,其中一半用于药物/化学数据,另一半用于药物靶标或蛋白质数据。
4. 搜索功能:DrugBank支持全面而复杂的搜索,便于新的药物靶目标、比较药物结构、研究药物机制以及探索新型药物。
5. 药物靶点链接:DrugBank提供了药物靶点(Drug-UniProt Links)、酶(Enzyme Drug-UniProt Links)、载体(Carrier Drug-UniProt Links)和转运体(Transporter Drug-UniProt Links)的链接。
6. 蛋白质标识符和序列:提供了蛋白质标识符,包括外部资源的ID,如UniProt和PDB,以及目标序列(Target Sequences)数据,这些数据以FASTA格式提供。

④ChEMBL数据库
ChEMBL数据库,由欧洲生物信息研究所(EMBL-EBI)开发,是一个开放获取的资源,它从广泛的文献中搜集了众多靶点和化合物的生物活性数据。这个数据库用于查询特定靶点或化合物的生物活性数据。EMBL-EBI的数据覆盖了基因组学、蛋白质、表达数据、小分子、蛋白质结构、系统生物学、本体论和科学文献等多个领域。目前,ChEMBL收录了超过15398个不同的靶标和超过239万种化合物。可以利用这个数据库迅速查找到特定靶点已知的化合物及其活性详情,同样也能检索出特定化合物在不同靶点上进行的生物活性测试结果和相关数据。
ChEMBL数据库特点介绍
1. 开放数据:ChEMBL数据库免费提供使用,包含超过1百万种化合物和超过1800万条关于它们对生物系统影响的记录。
2. 药物靶点链接:ChEMBL数据库中的每个靶点或多个靶点都可以通过简单的下拉菜单显示所有相关的生物活性数据,或过滤特定活动类型的数据。
3. 数据内容:数据库包含关于小分子如何与它们的蛋白靶标相互作用、这些化合物如何影响细胞和整个生物体、以及吸收、分布、代谢、排泄和毒性(ADMET)的信息。
4. 检索:可以通过关键词、子结构或相似性进行搜索,并提供化合物报告卡以获取详细信息。ChEMBL还提供了Web服务界面,允许用户以不同的格式检索不同类型资源,如结构SVG图。
5. 新发展:ChEMBL不断扩展其数据模型,包括临床候选药物的数据、专利中的数据、针对被忽视疾病和农业化学数据的直接沉积。
6. 数据提取和策划:数据主要从主要的医学化学和药理学文献中手动提取和策划的结构-活性关系(SAR)数据。
⑤Bindind Database(以下简称BindingDB)
BindingDB,由美国加州大学圣地亚哥分校的斯卡格斯药剂学与制药科学学院开发,是一个向公众开放的数据库,专注于搜集药物靶点蛋白和药物小分子之间的相互作用及其亲和力数据。该数据库涵盖了近百万条靶点与配体的结合信息,使其成为查询特定药物靶点相关配体信息的首选资源。
BindingDB数据库特点介绍
1.数据来源与类型:BindingDB的数据来自PDB相关文献报道数据、专利信息、PubChem BioAssays数据和ChEMBL记录数据。亲和力数据包括酶抑制活性和酶动力学、等温滴定量热法(ITC)、核磁共振(NMR)以及放射性配体竞争测定法等,数据类型涵盖Ki、IC50、Kd、EC50等。
2.数据库内容:BindingDB包含了超过110万个化合物与8800个靶点之间的250万个相互作用数据。数据库还提供了通路信息、化合物ZINC编号以及其他信息。
3.外部数据库整合:BindingDB与PDB、PubMed、DrugBank等多个外部数据库网站进行整合,提供数据互访链接,同时也是PDB数据库中受体-配体结合亲和力的数据来源之一。
4.检索与下载:用户可以通过靶点名称、靶点序列、药物名称、药物结构和通路信息等多种方式进行检索。
5.BindingDB通过文献意识和结构-活性关系的发展(SAR和QSAR)支持药物化学和药物发现;验证计算化学和分子建模方法。


















 川公网安备51019002008863号
川公网安备51019002008863号 本网站未发布麻醉药品、精神药品、医疗用毒性药品、放射性药品、戒毒药品和医疗机构制剂的产品信息
本网站未发布麻醉药品、精神药品、医疗用毒性药品、放射性药品、戒毒药品和医疗机构制剂的产品信息
收藏
登录后参与评论
暂无评论